
摩尔线程新法子优化AI交互:显存俭省最多82%
栏目:行业动态 发布时间:2025-03-06 08:43
摩尔线程科研团队克日宣布了一项新的研讨结果《Round Attention:以轮次块稀少性开拓多轮对...
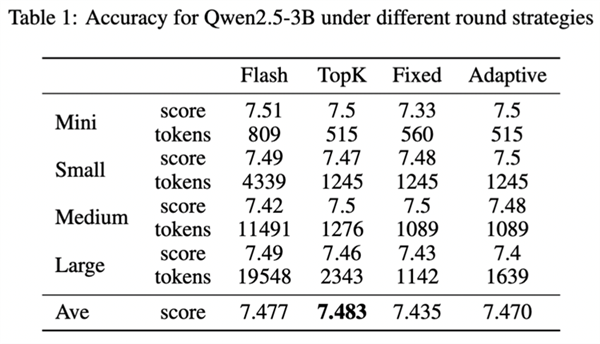
摩尔线程科研团队克日宣布了一项新的研讨结果《Round Attention:以轮次块稀少性开拓多轮对话优化新范式》,使得端到端耽误低于当初主流的Flash Attention推理引擎,kv-cache显存占用节俭最多82%。比年来,AI年夜型言语模子的提高,推进了言语模子效劳在一样平常成绩处理义务中的普遍利用。但是,长时光的交互裸露出两滚球十大信誉平台年夜明显成绩:起首,高低文长度的疾速扩大因自留神力机制的平方级庞杂度而招致宏大的盘算188BET手机版开支;其次,只管键值(KV)缓存技巧能缓解冗余盘算,但明显增添的GPU内存需要,招致推理批处置范围受限,同时GPU应用率低下。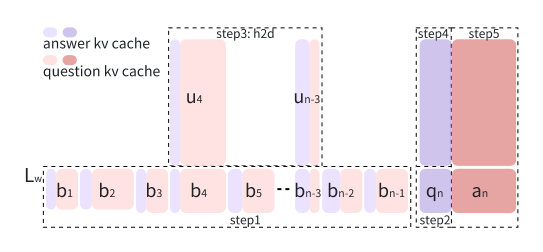 为此,摩尔线程提出了Round Attention,以处理这些成绩。起首,摩尔线程提沙巴体育app出以轮次为剖析单位研讨Attention法则:Round Attention专为多轮对话场景推理需要计划,以轮次为天然界限分别KV缓存。研讨发明,轮次粒度的Attention散布存在两个主要法则。其次,摩尔线程提出了Round Attention推理流水线;基于发明的两个法则,将稀少性从Token级晋升至块级,拔取最相干的块参加attention盘算,增加attention盘算耗时,并将不相干的块卸载到CPU内存,以节俭显存占用。这在坚持推理精度的情形下,增加了推理耗时,下降了显存占用。摩尔线程以为,轮次块稀少性有三年夜上风:天然界限的语义完全性、分水岭层的留神力稳固性、端到真个存储与传输优化。测试表现,Round Attention的端到端耽误低于当初主流的Flash Attention推理引擎, kv-cache显存占用则节俭55-82%,而且在客观评测跟客不雅评测两个数据集上,模子推理正确率基础未受影响。
为此,摩尔线程提出了Round Attention,以处理这些成绩。起首,摩尔线程提沙巴体育app出以轮次为剖析单位研讨Attention法则:Round Attention专为多轮对话场景推理需要计划,以轮次为天然界限分别KV缓存。研讨发明,轮次粒度的Attention散布存在两个主要法则。其次,摩尔线程提出了Round Attention推理流水线;基于发明的两个法则,将稀少性从Token级晋升至块级,拔取最相干的块参加attention盘算,增加attention盘算耗时,并将不相干的块卸载到CPU内存,以节俭显存占用。这在坚持推理精度的情形下,增加了推理耗时,下降了显存占用。摩尔线程以为,轮次块稀少性有三年夜上风:天然界限的语义完全性、分水岭层的留神力稳固性、端到真个存储与传输优化。测试表现,Round Attention的端到端耽误低于当初主流的Flash Attention推理引擎, kv-cache显存占用则节俭55-82%,而且在客观评测跟客不雅评测两个数据集上,模子推理正确率基础未受影响。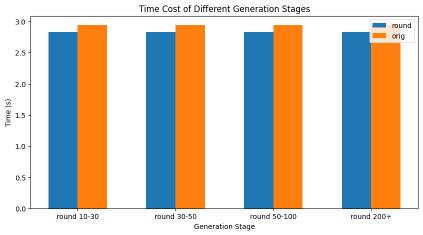
 【本文停止】如需转载请务必注明出处:快科技义务编纂:上方文Q
【本文停止】如需转载请务必注明出处:快科技义务编纂:上方文Q
为此,摩尔线程提出了Round Attention,以处理这些成绩。起首,摩尔线程提沙巴体育app出以轮次为剖析单位研讨Attention法则:Round Attention专为多轮对话场景推理需要计划,以轮次为天然界限分别KV缓存。研讨发明,轮次粒度的Attention散布存在两个主要法则。其次,摩尔线程提出了Round Attention推理流水线;基于发明的两个法则,将稀少性从Token级晋升至块级,拔取最相干的块参加attention盘算,增加attention盘算耗时,并将不相干的块卸载到CPU内存,以节俭显存占用。这在坚持推理精度的情形下,增加了推理耗时,下降了显存占用。摩尔线程以为,轮次块稀少性有三年夜上风:天然界限的语义完全性、分水岭层的留神力稳固性、端到真个存储与传输优化。测试表现,Round Attention的端到端耽误低于当初主流的Flash Attention推理引擎, kv-cache显存占用则节俭55-82%,而且在客观评测跟客不雅评测两个数据集上,模子推理正确率基础未受影响。【本文停止】如需转载请务必注明出处:快科技义务编纂:上方文Q 